 Seldon Enterprise Platform Documentation Update
Seldon Enterprise Platform Documentation Update
Batch Prediction Requests¶
Pre-requisites¶
MinIO should already be installed with Seldon Enterprise Platform.
The MinIO browser should be exposed on /minio/ (note the trailing forward slash).
For trials, the credentials will by default be the same as the Enterprise Platform login, with MinIO using the email as its Access Key and the password as its Secret Key.
Note
Other cloud storage services, such as S3 and GCS, can be specified alternatively with the corresponding secret files configured.
On a production cluster, the namespace needs to have been set up with a service account. This can be found under the argo install documentation.

We will:
Deploy a deployment with a pretrained SKlearn iris model
Run a batch job to get predictions
Check the output
Create a Deployment¶
Click on
Create new deploymentbutton.Enter the deployment details as follows:
Name: batch-demo
Namespace: seldon
Type: Seldon Deployment
Protocol: Seldon
Expand to see Seldon deployment details
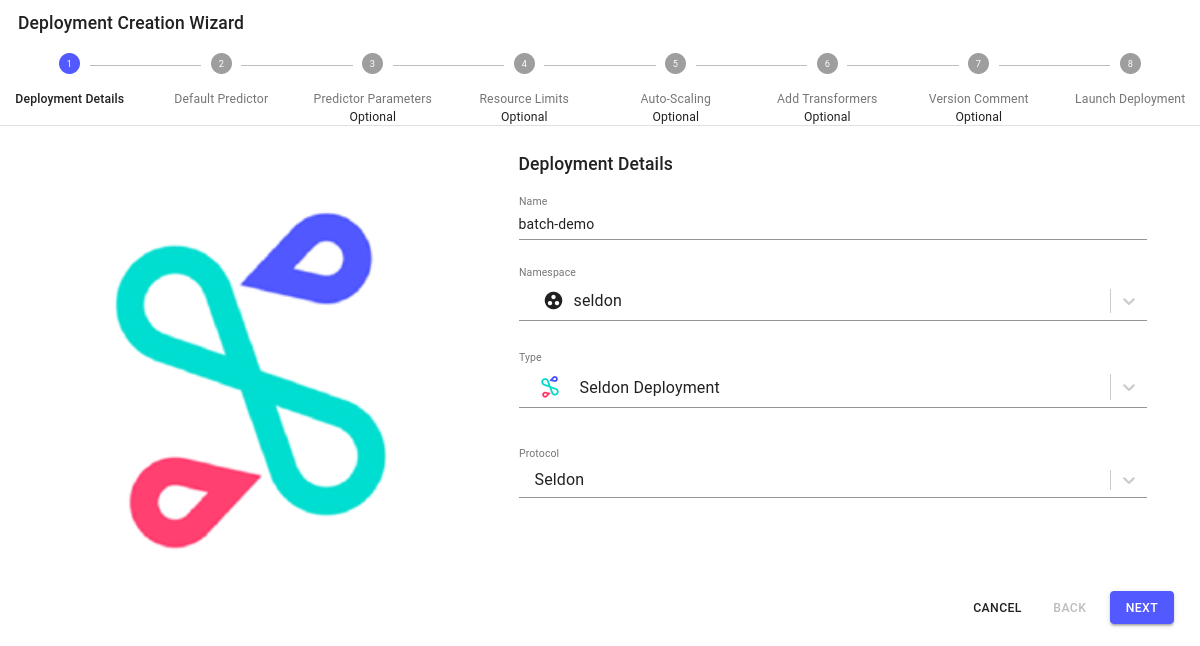
Configure the default predictor as follows:
Runtime: Scikit Learn
Model URI:
gs://seldon-models/v1.18.2/sklearn/irisModel Project: default
Storage Secret: (leave blank/none)
Additional Model Requirements: (leave blank/none)
Skip
Nextfor the remaining steps, then clickLaunch.If your deployment is launched successfully, it will have
Availablestatus, on the overview page.
Setup Input Data¶
Download the
input data file. The first few lines of the input file ‘input-data.txt’ should show the following format:[[0.5488135039273248, 0.7151893663724195, 0.6027633760716439, 0.5448831829968969]] [[0.4236547993389047, 0.6458941130666561, 0.4375872112626925, 0.8917730007820798]] [[0.9636627605010293, 0.3834415188257777, 0.7917250380826646, 0.5288949197529045]]
Go to the MinIO browser and use the button in the bottom-right to create a bucket. Call it
data.Expand to see MinIO bucket creation
Again from the bottom-right choose to upload the
input-data.txtfile to thedatabucket.Expand to see MinIO file upload

Run a Batch Job¶
Click on the tile for your new deployment called
batch-demoin the Overview page of the Enterprise Platform UI.Go to the Batch Jobs section for this deployment by clicking on the
Batch Jobsbutton in the sidebar on the left.Click on the
Create your first jobbutton, enter the following details, and clickSubmit:Input Data Location:
minio://data/input-data.txtOutput Data Location:
minio://data/output-data-{{workflow.name}}.txtNumber of Workers: 5
Number of Retries: 3
Batch Size: 10
Minimum Batch Wait Interval (sec) : 0
Method: Predict
Transport Protocol: REST
Input Data Type: ndarray
Object Store Secret Name: minio-bucket-envvars
Expand to see batch job setup
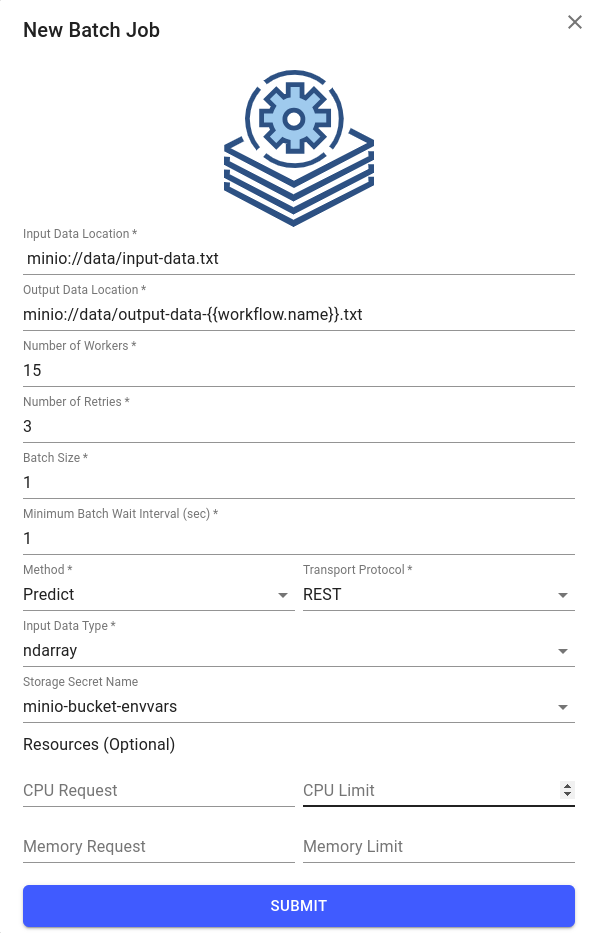
Note
Here
minio-bucket-envvarsis a pre-created secret in the same namespace as the model, containing environment variables.Note
In the
Resources (Optional)section, you can specify how much memory and CPU are allocated to the containers in this specific batch job workflow. If no values are set on this form, the default values specified in Helm values will be used. Refer to the Kubernetes documentation on requests and limits for details.Give the job a couple of minutes to complete, then refresh the page to see the status.
Expand to see batch job status
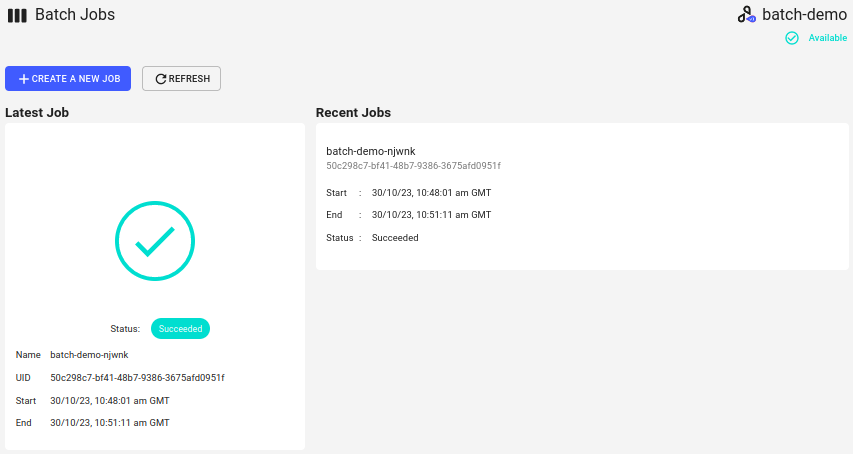
Inspect the output file in MinIO:
Expand to see MinIO output file
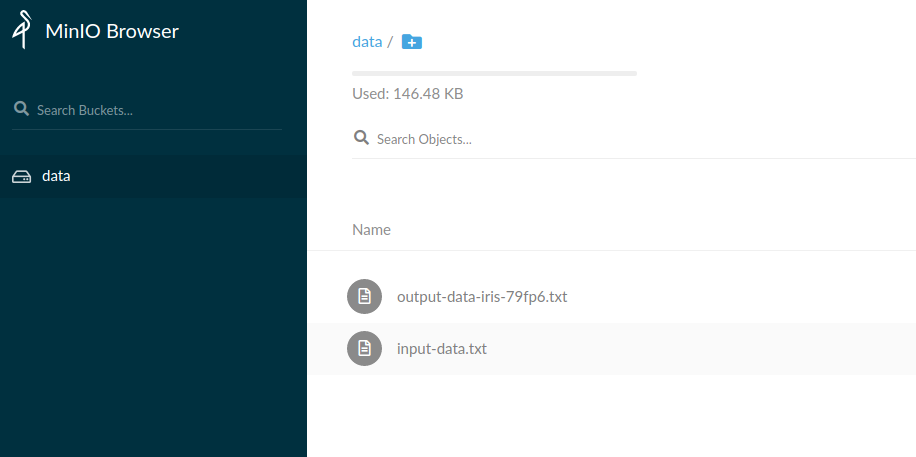
If you open that file you should see contents such as:
{"data": {"names": ["t:0", "t:1", "t:2"], "ndarray": [[0.0006985194531162841, 0.003668039039435755, 0.9956334415074478]]}, "meta": {"requestPath": {"iris-container": "seldonio/sklearnserver:1.5.0-dev"}, "tags": {"tags": {"batch_id": "8a8f5e26-2b44-11eb-8723-ae3ff26c8be6", "batch_index": 3.0, "batch_instance_id": "8a8ff94e-2b44-11eb-b8d0-ae3ff26c8be6"}}}} {"data": {"names": ["t:0", "t:1", "t:2"], "ndarray": [[0.0006985194531162841, 0.003668039039435755, 0.9956334415074478]]}, "meta": {"requestPath": {"iris-container": "seldonio/sklearnserver:1.5.0-dev"}, "tags": {"tags": {"batch_id": "8a8f5e26-2b44-11eb-8723-ae3ff26c8be6", "batch_index": 6.0, "batch_instance_id": "8a903666-2b44-11eb-b8d0-ae3ff26c8be6"}}}} {"data": {"names": ["t:0", "t:1", "t:2"], "ndarray": [[0.0006985194531162841, 0.003668039039435755, 0.9956334415074478]]}, "meta": {"requestPath": {"iris-container": "seldonio/sklearnserver:1.5.0-dev"}, "tags": {"tags": {"batch_id": "8a8f5e26-2b44-11eb-8723-ae3ff26c8be6", "batch_index": 1.0, "batch_instance_id": "8a8fbe98-2b44-11eb-b8d0-ae3ff26c8be6"}}}}
If not, see the argo section for troubleshooting.
Micro batching¶
You can specify a batch-size parameter which will group multiple predictions into a single request.
This allows you to take advantage of the higher performance batching provides for some models, and reduce networking overhead.
The response will be split back into multiple, single-prediction responses
so that the output file looks identical to running the processor with a batch size of 1.
Note
Currently, we only support micro batching for ndarray and tensor payload types.