 Seldon Enterprise Platform Documentation Update
Seldon Enterprise Platform Documentation Update
Model Drift Detection¶
When ML models are deployed in production, sometimes even minor changes in a data distribution can adversely affect the performance of ML models. When the input data distribution shifts then prediction quality can drop. It is important to track this drift. This demo is based on the mixed-type tabular data drift detection method in the alibi detect project for tabular datasets.
Here we will :
Launch an income classifier model based on demographic features from a 1996 US census. The data instances contain a person’s characteristics like age, marital status or education while the label represents whether the person makes more or less than $50k per year.
Setup a mixed-type tabular data drift detector for this particular model.
Make a batch of predictions over time
Track the drift metrics in the Monitoring dashboard.
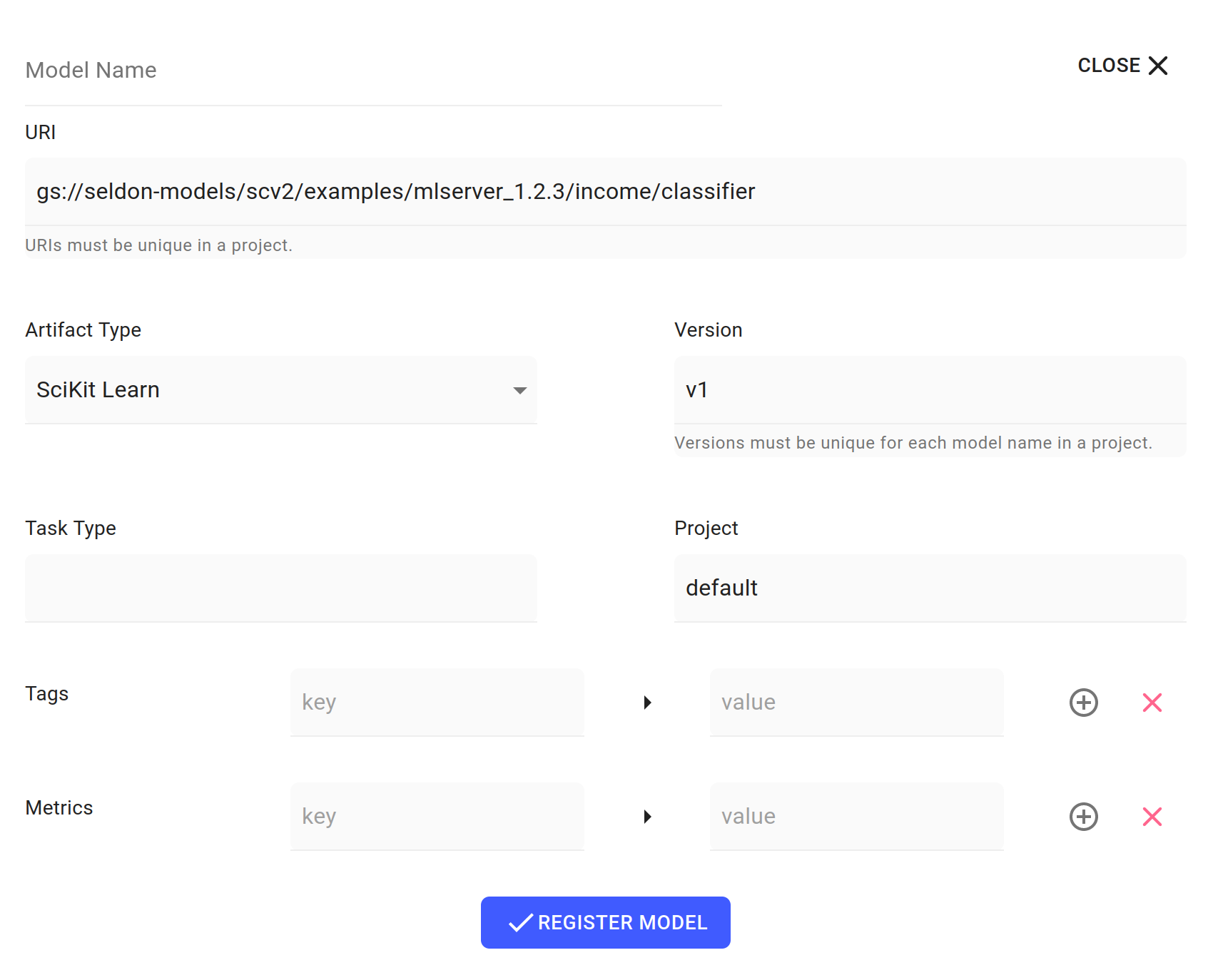
Register an income classifier model¶
Register a pre-trained income classifier SKLearn model with model artefacts.
In the
Model Catalogpage, click theRegister New Modelbutton:Expand to see the 'Register New Model' button

In the
Register New Modelwizard, enter the following information, then clickREGISTER MODEL:Model Name:
income-classifierURI:
gs://seldon-models/scv2/samples/mlserver_1.6.0/income-sklearn/classifier/Artifact Type:
SciKit LearnVersion:
v1
Expand to see model configuration
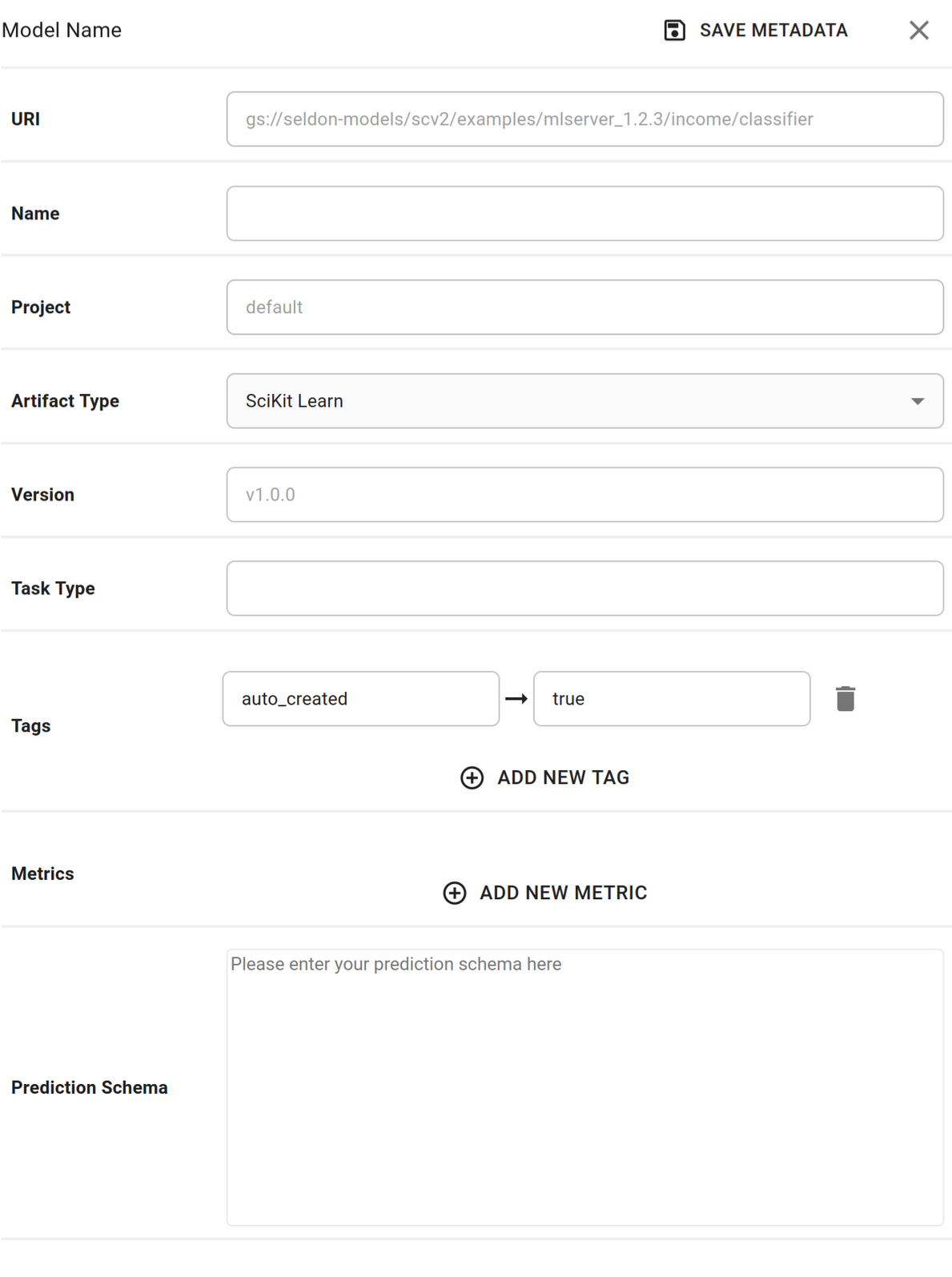
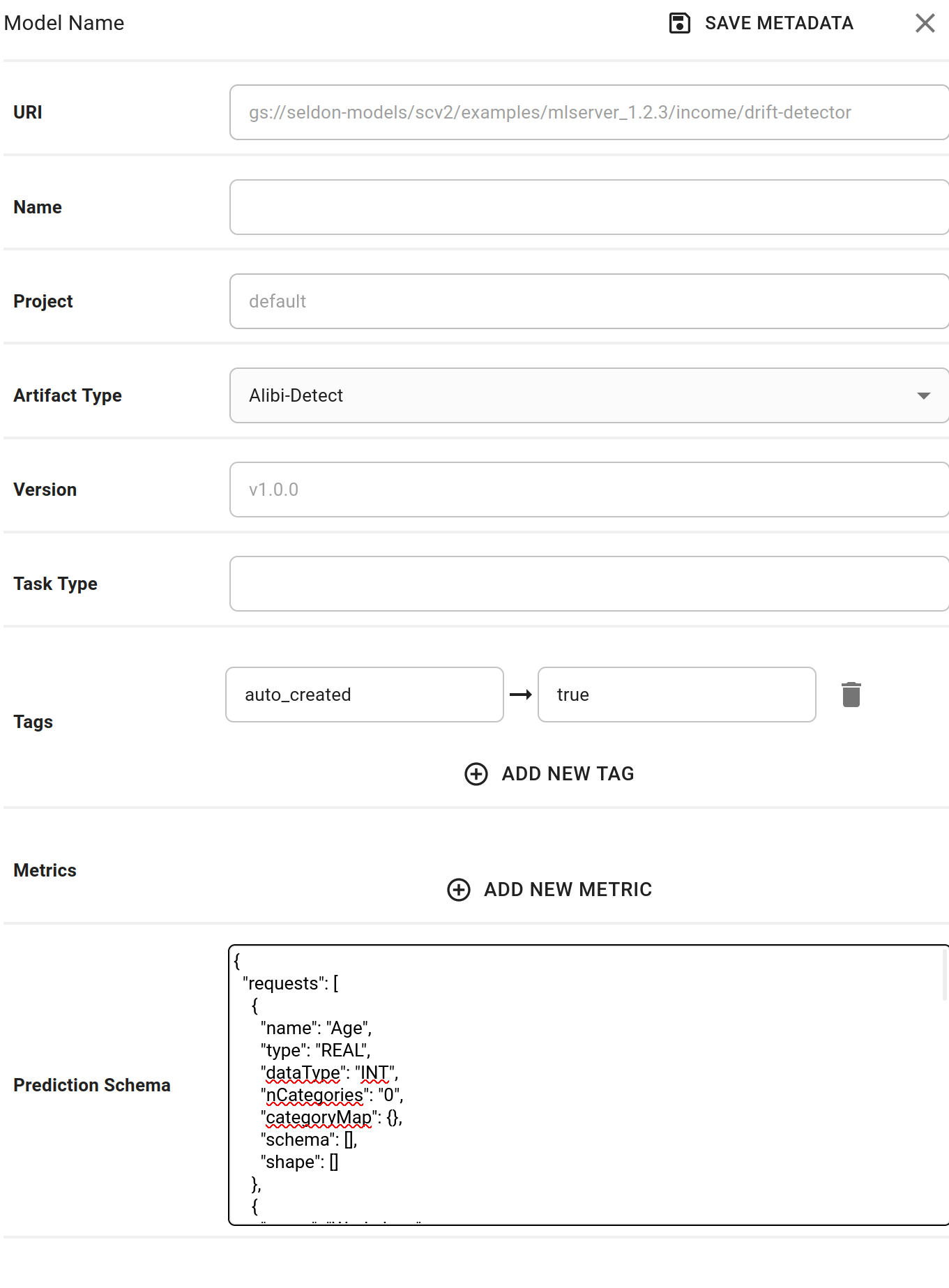
Configure predictions schema for classifier¶
Edit the model metadata to update the prediction schema for the model. The prediction schema is a generic schema structure for machine learning model predictions. It is a definition of feature inputs and output targets from the model prediction. Use the income classifier model predictions schema to edit and save the model level metadata. Learn more about the predictions schema at the ML Predictions Schema open source repository.
Click on the model
income-classifiermodel that you have just registered.Expand to see select model

Click the
Edit Metadatabutton to update the prediction schema associated with the modelExpand to see 'Edit Metadata' button
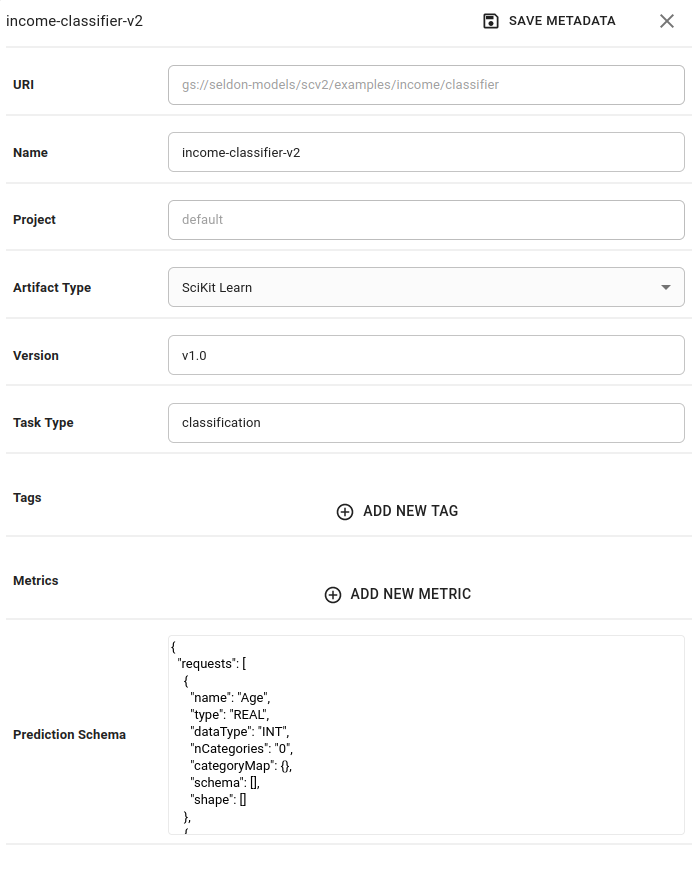
Paste the
prediction schemaand clickSave Metadata.Expand to see configure prediction schema
Launch a Seldon ML Pipeline¶
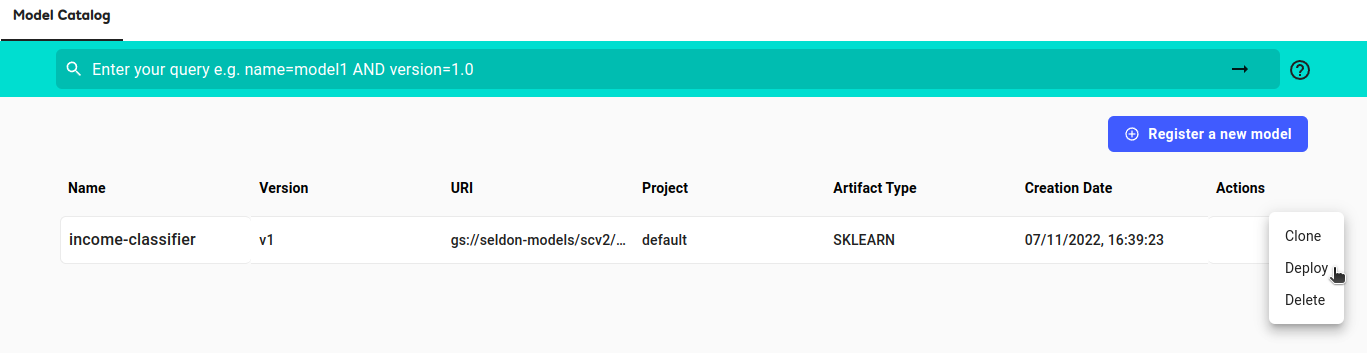
Deploy the income classifier model from the catalog into an appropriate namespace
From the model catalog, under the
Actiondropdown list, selectDeploy.Expand to see deploy model
Enter the deployment details in the deployment creation wizard and click
Next:Name:
income-drift-demoType:
Seldon ML Pipeline
Expand to see deploy model
In the deployment creation wizard, enter a name for your new deployment (e.g.
income-drift-demo). Select the namespace you would like the deployment to reside in (e.g.seldon) and clickNext.
The predictor details should already be filled in from the model catalog. Click
Next:Expand to see default predictor details
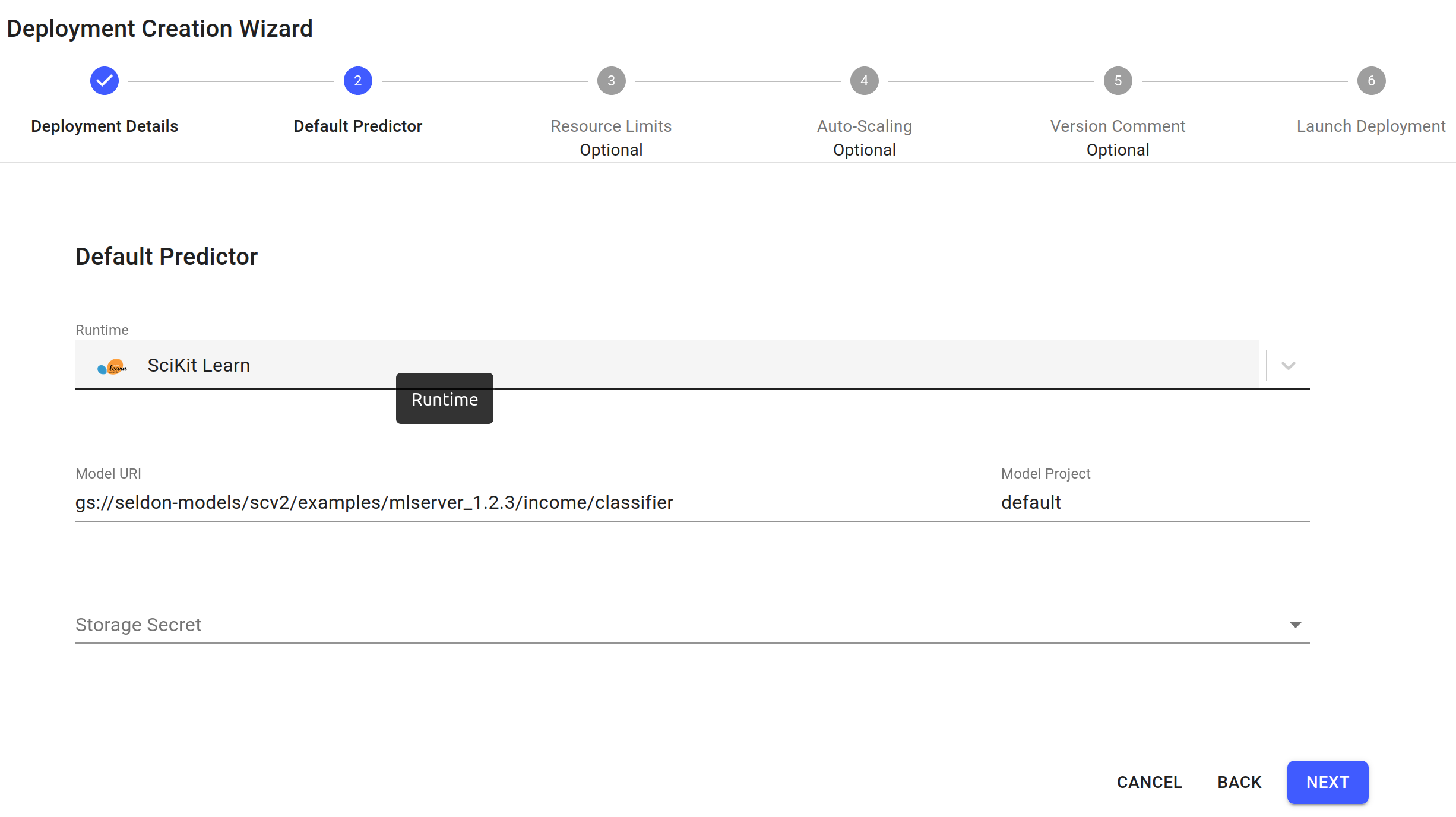
Click
Nextfor the remaining steps, then clickLaunch.
Add A Drift Detector¶
From the deployment overview page, select your deployment to enter the deployment dashboard. Inside the deployment dashboard, add a drift detector with by clicking the Create button within the DRIFT DETECTION widget.
Expand to see drift detector creation

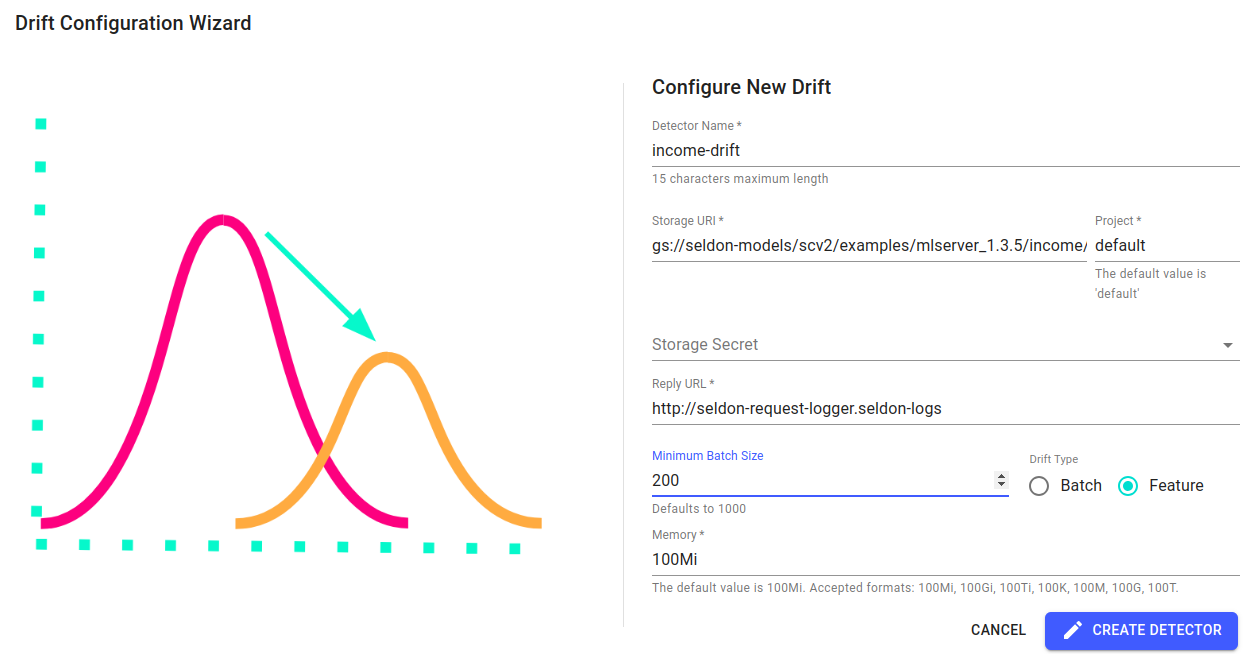
Enter the following parameters in the modal popup which appears, to configure the detector:
Detector Name:
income-drift.Model URI: (For public google buckets, secret field is optional)
gs://seldon-models/scv2/examples/mlserver_1.3.5/income/drift-detector
Reply URL: (By default, the Reply URL is set as
seldon-request-loggerin the logger’s default namespace. If you are using a custom installation, please change this parameter according to your installation.)http://seldon-request-logger.seldon-logs
Minimum Batch Size:
200Drift Type:
Feature
Then, click CREATE DETECTOR to complete the setup.
Configure predictions schema for detector¶
As per the income classifier model, use the same model predictions schema to edit and save the model level metadata for drift detector.
Click on the vertical ellipses “⋮” icon for the drift detector you have just registered.
Expand to see the dropdown for the Detector
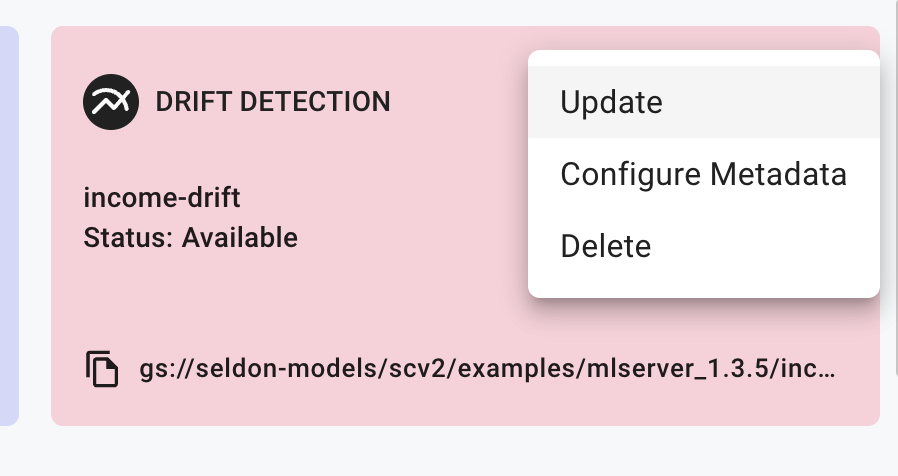
Click the
Configure Metadataoption to update the prediction schema associated with the modelExpand to see the 'Configure Metadata' modal
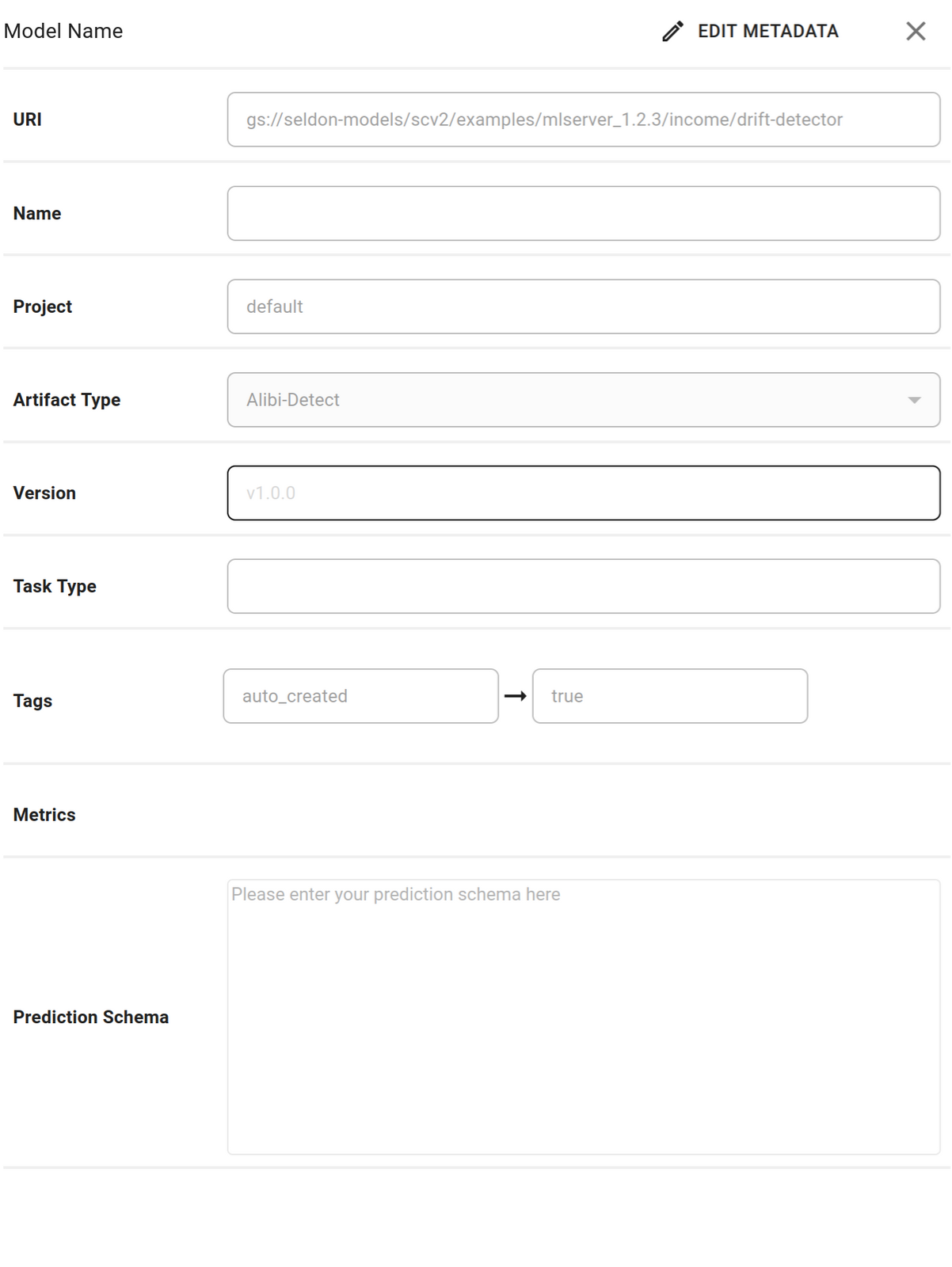
Paste the
prediction schema, name the modelincome-driftand clickSave Metadata.Expand to see configure prediction schema
Run Batch Predictions¶
From the deployment dashboard, click on
Batch Jobs. Run a batch prediction job using the V2 payload format textpredictions data file. This file has 4000 individual data points and based on our drift detector configuration, drift will be detected for a batch every200points. The distribution of the data in the first half section is the same as the distribution of the reference data the drift detector was configured with and the second half section of the data should be different to observe drift.Upload the data to a bucket store of your choice. This demo will use MinIO and store the data at bucket path
minio://income-batch-data/data.txt. Do not forget to configure your storage access credentials secret - we have it asminio-bucket-envvarshere. Refer to the batch request demo for an example of how this can be done via the minio browser.Running a batch job with the configuration below. This runs an offline job that makes a prediction request for a batch of 200 rows in the file at
minio://income-batch-data/data.txtevery5 seconds:Input Data Location: minio://income-batch-data/data.txt Output Data Location: minio://income-batch-data/output-{{workflow.name}}.txt Number of Workers: 1 Number of Retries: 3 Batch Size: 200 Minimum Batch Wait Interval (sec): 5 Method: Predict Transport Protocol: REST Input Data Type: V2 Raw Storage Secret Name: minio-bucket-envvars
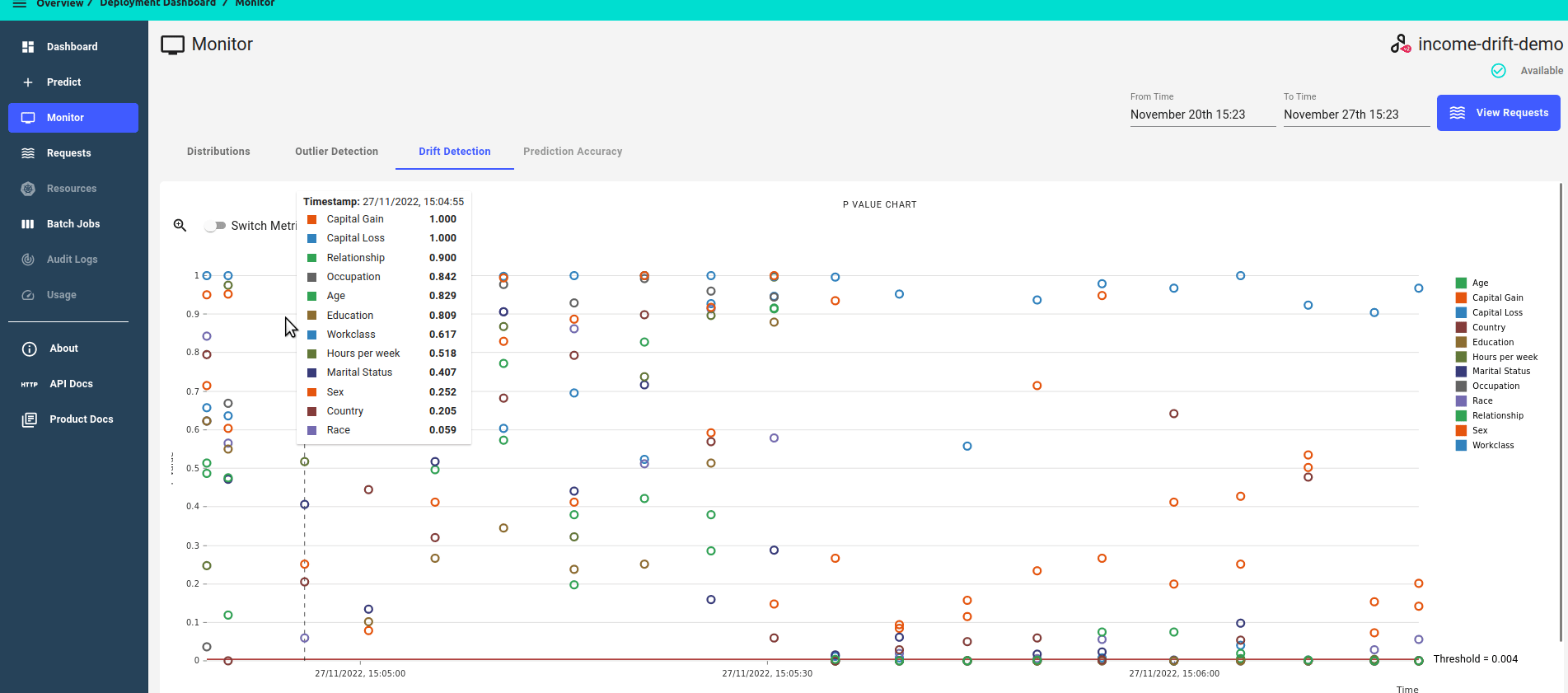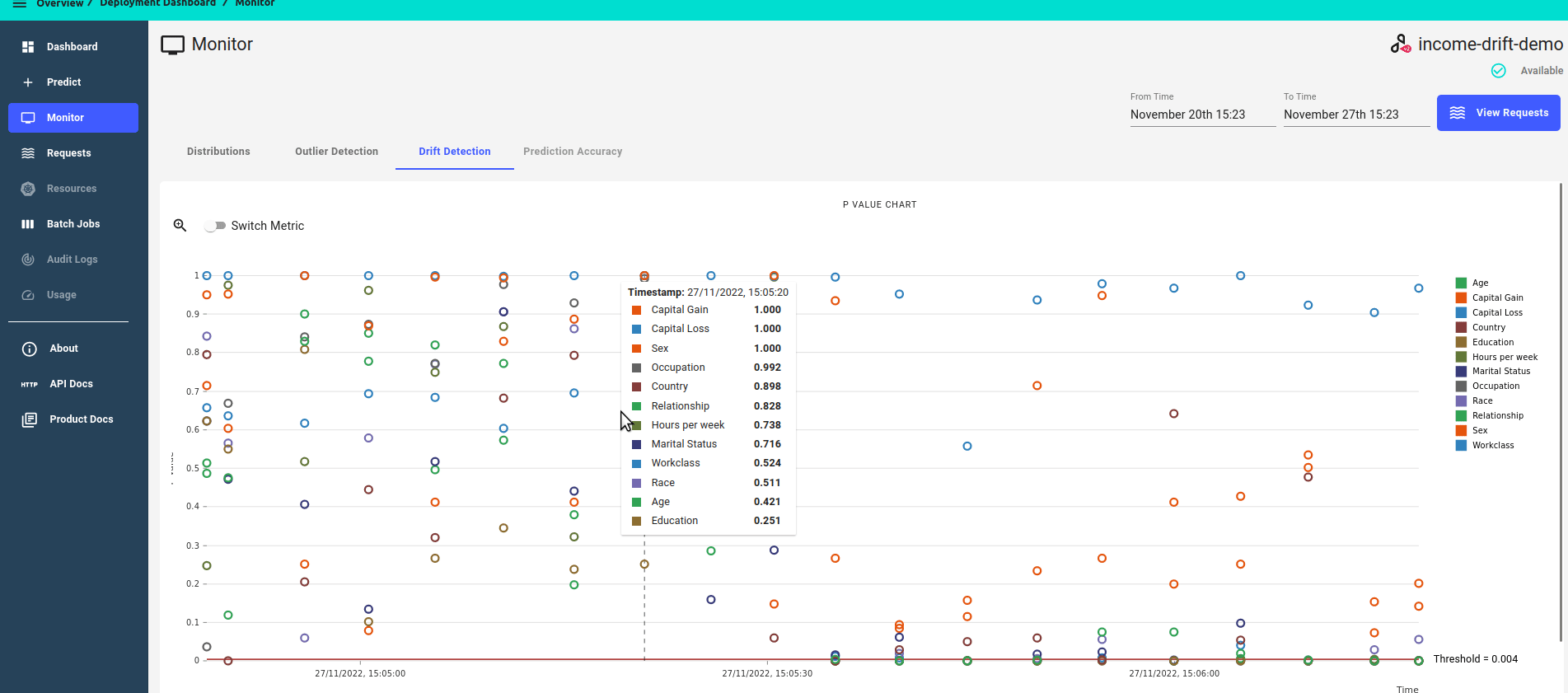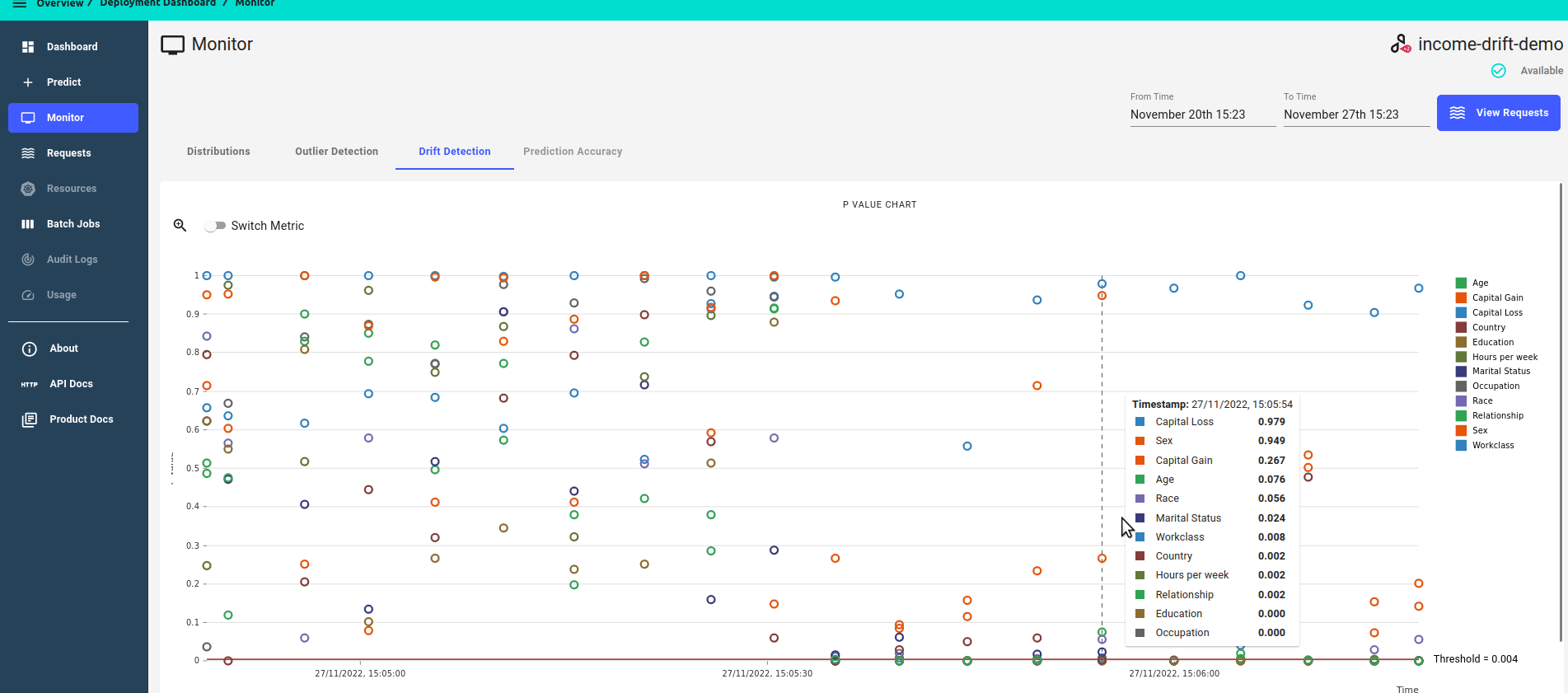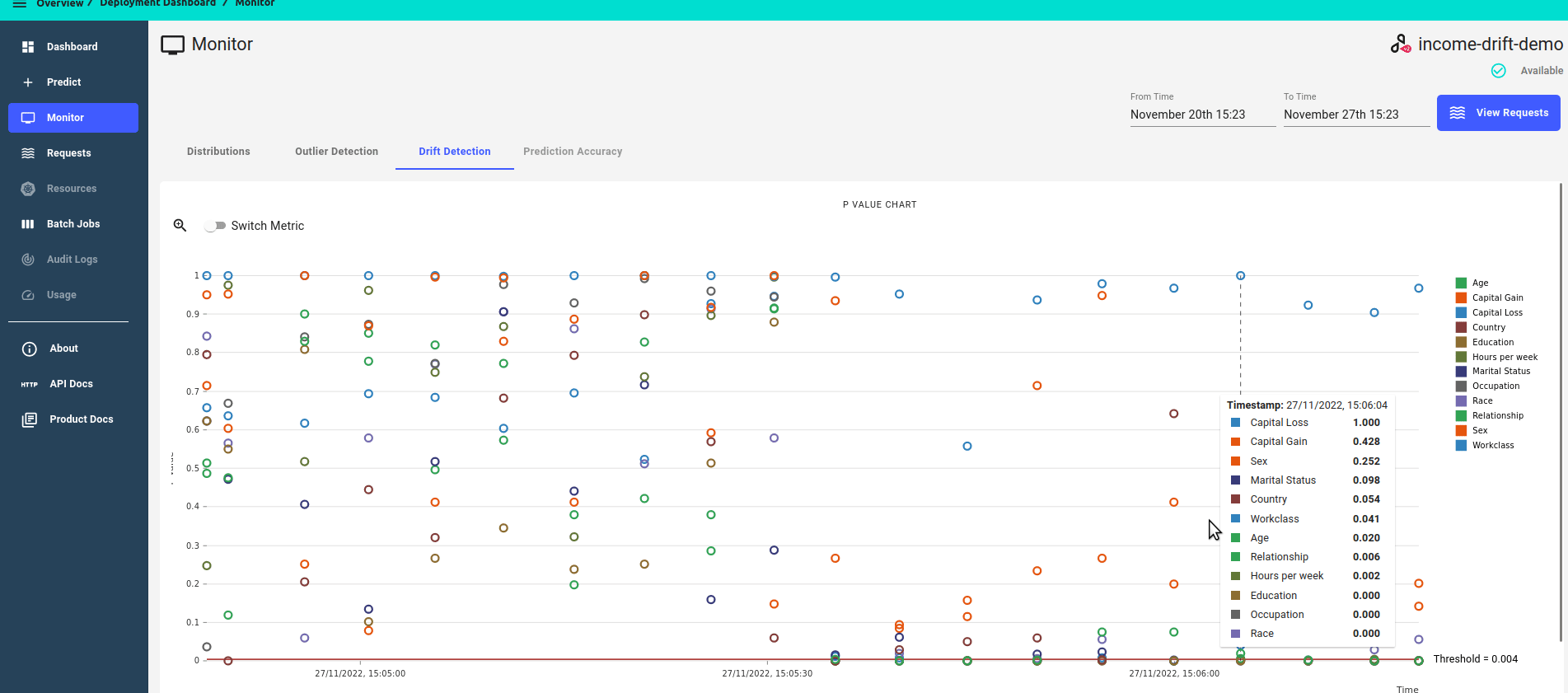
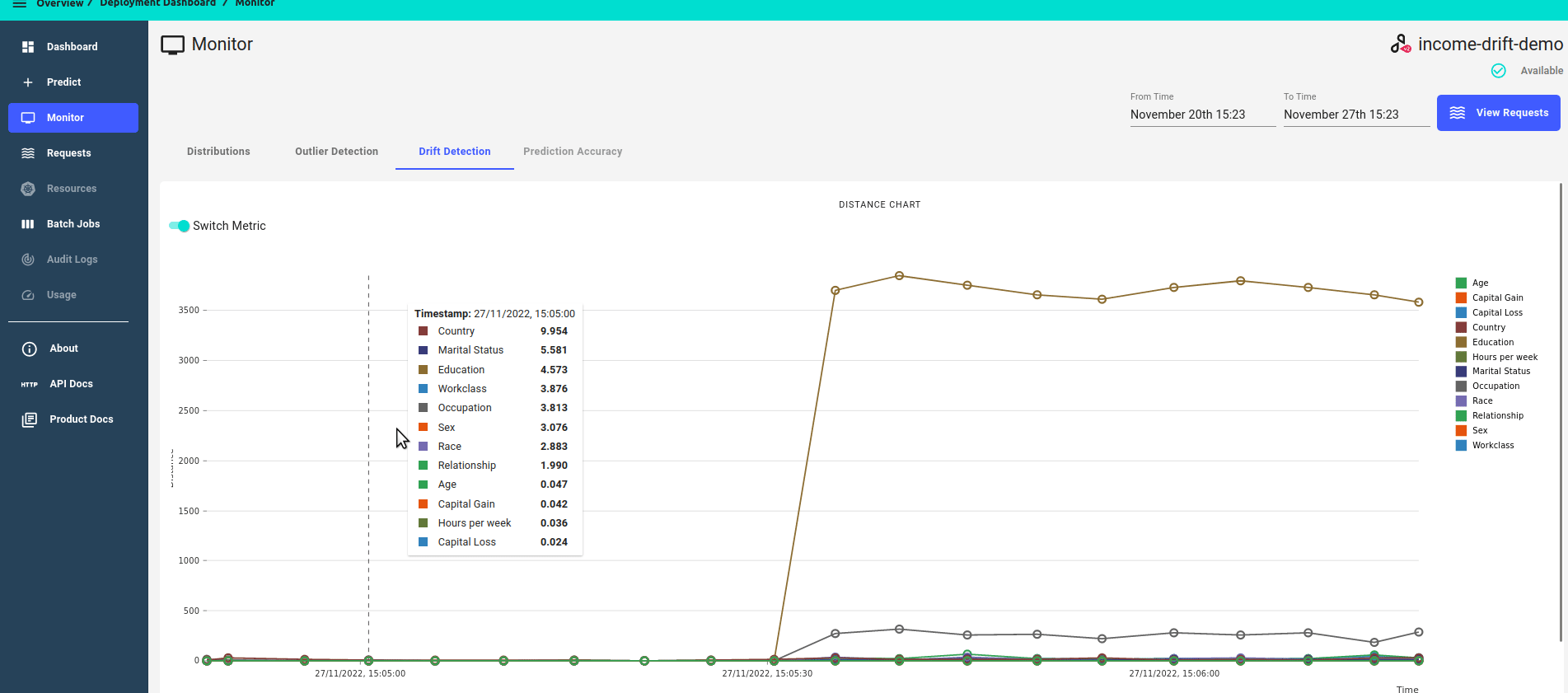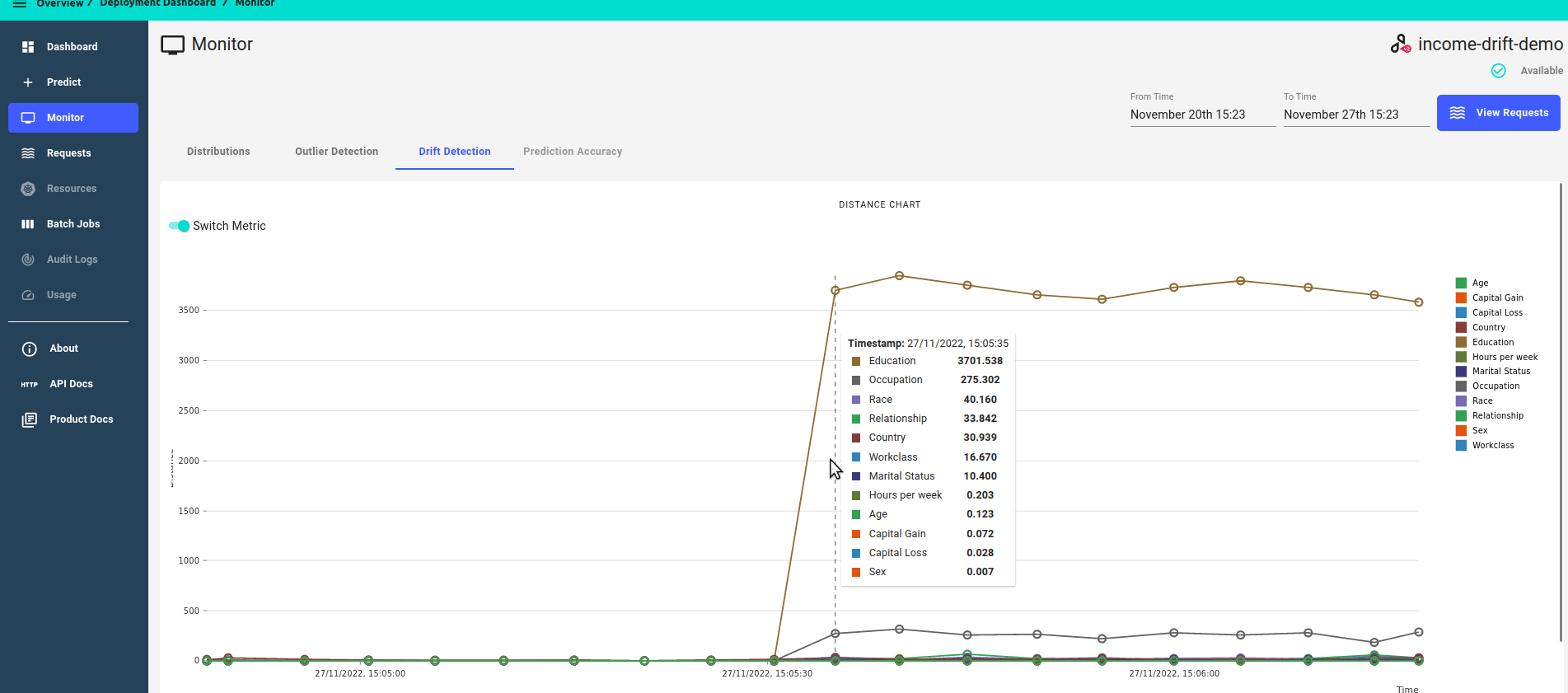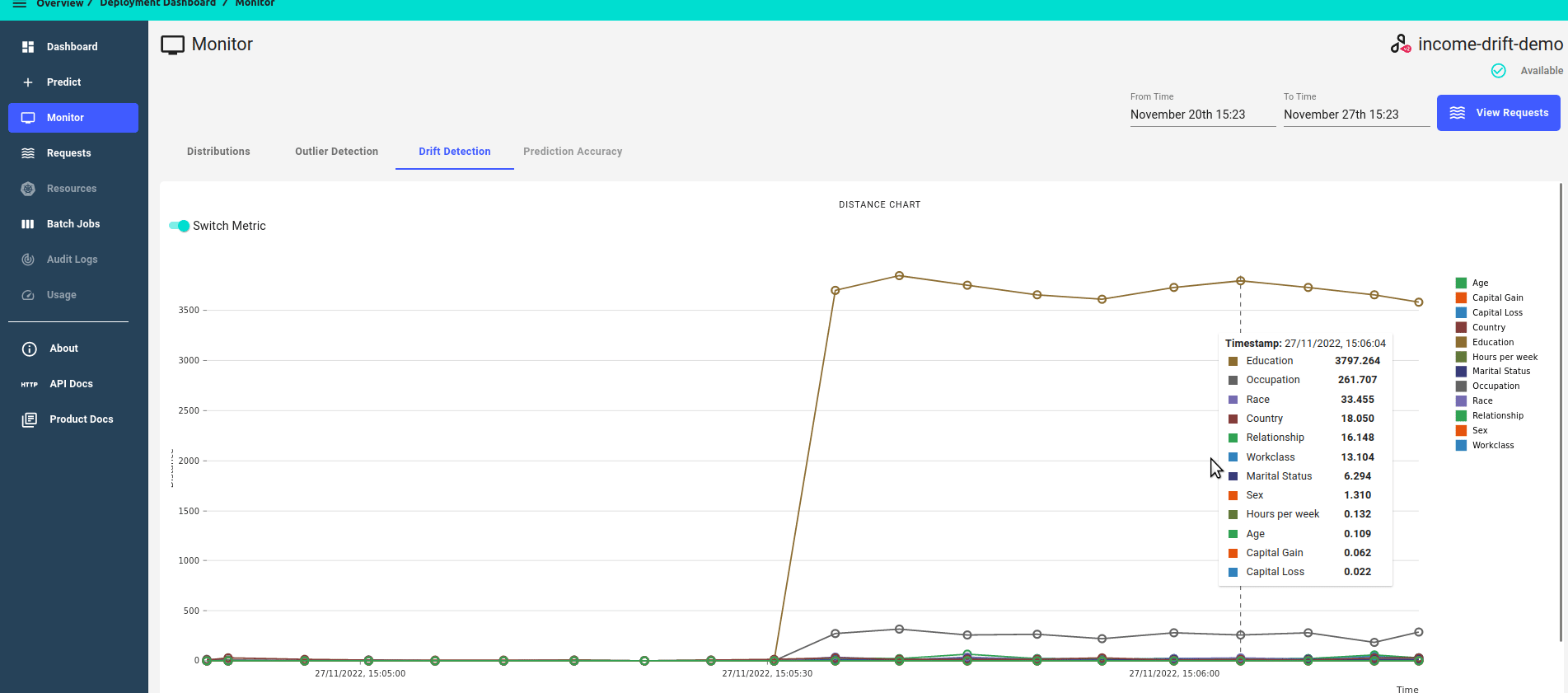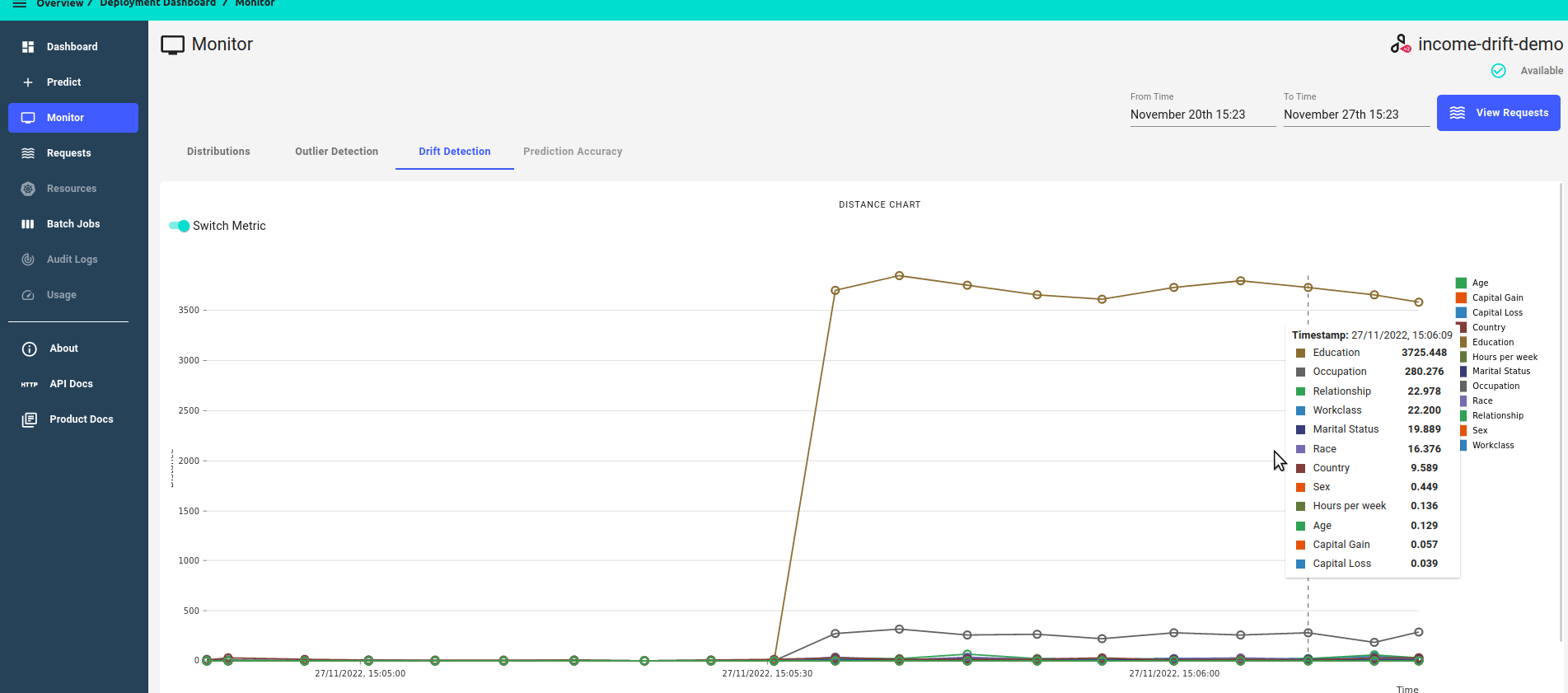
Monitor Drift Detection Metrics¶
Under the Monitor section of your deployment navigation, on the Drift Detection Tab, you can see a timeline of drift detection metrics.
The drift dashboard showcases 2 types of metrics graphs:
P-value score over time
Zoomed in view, focusing on features that have drifted, i.e. features that have a p-value score of less than the threshold.
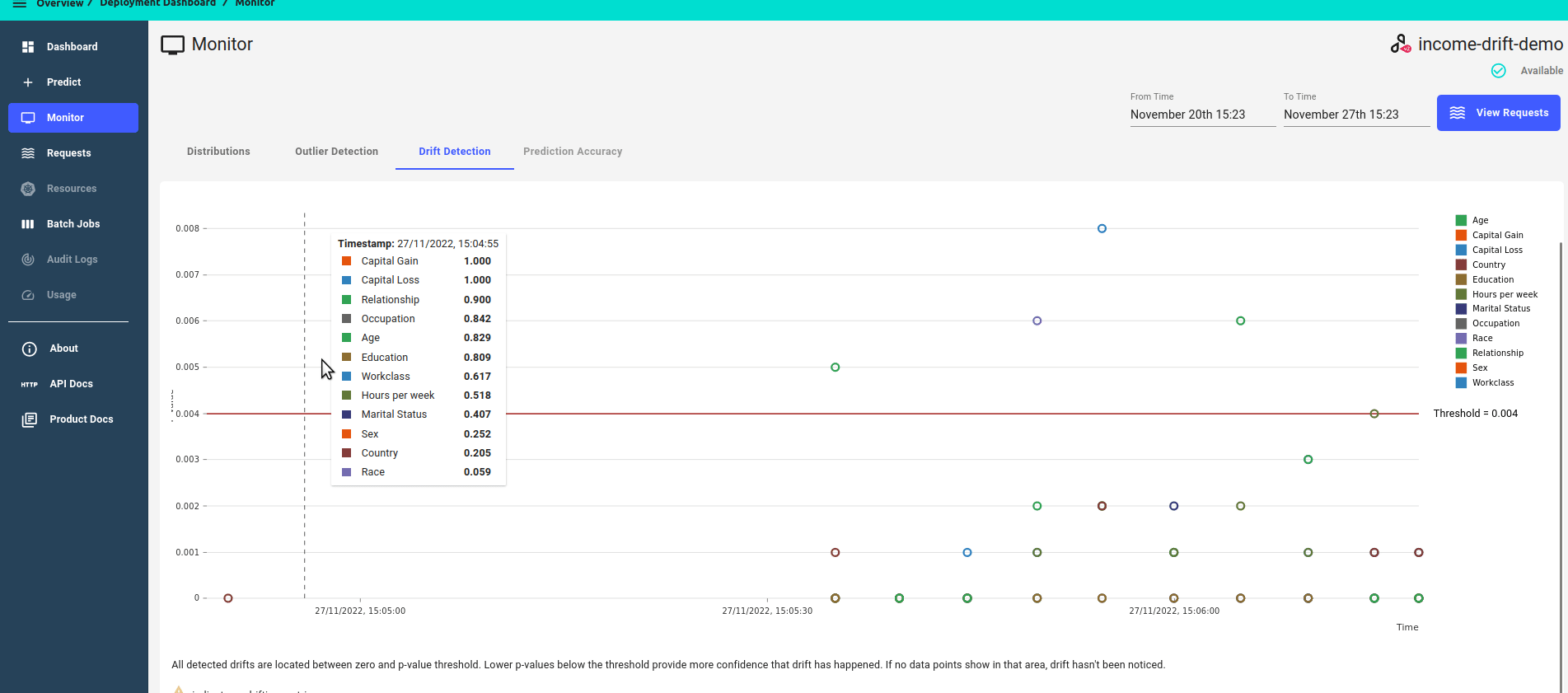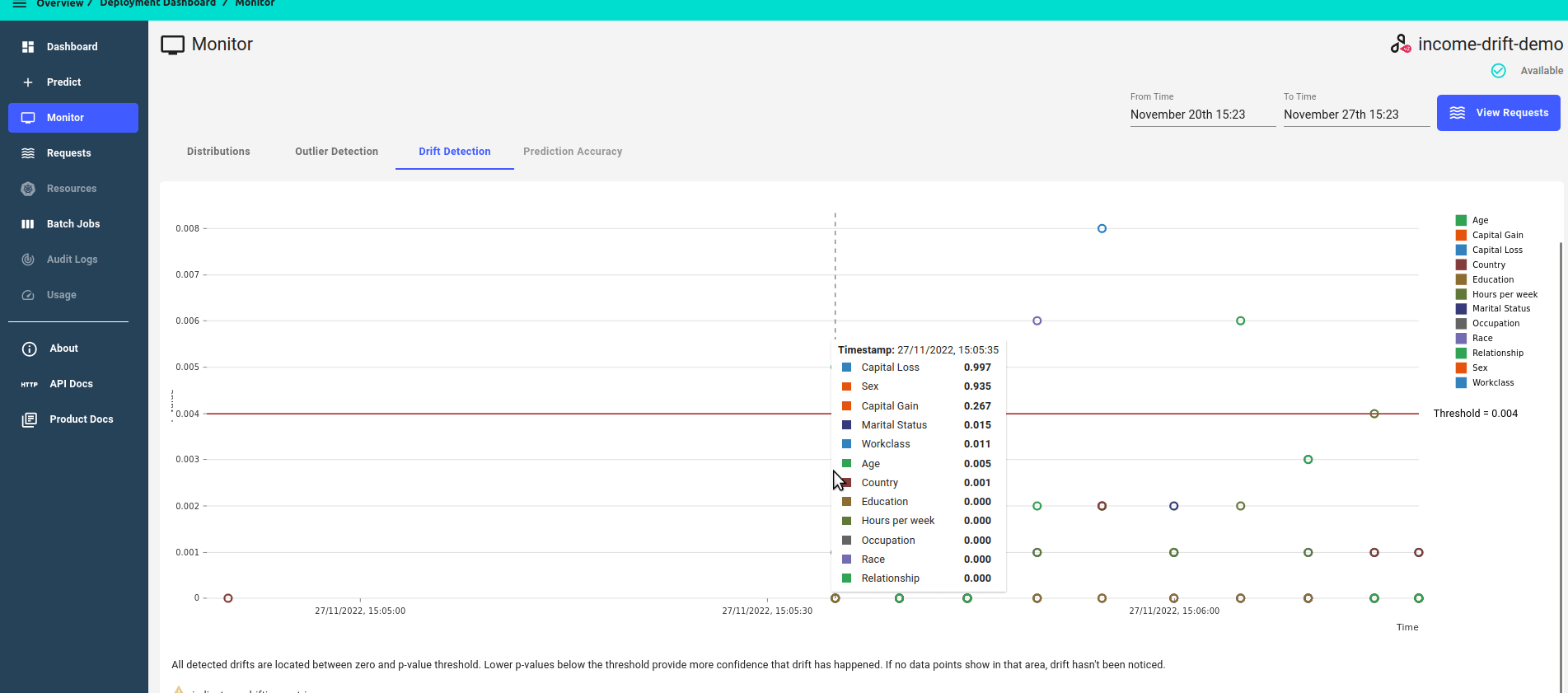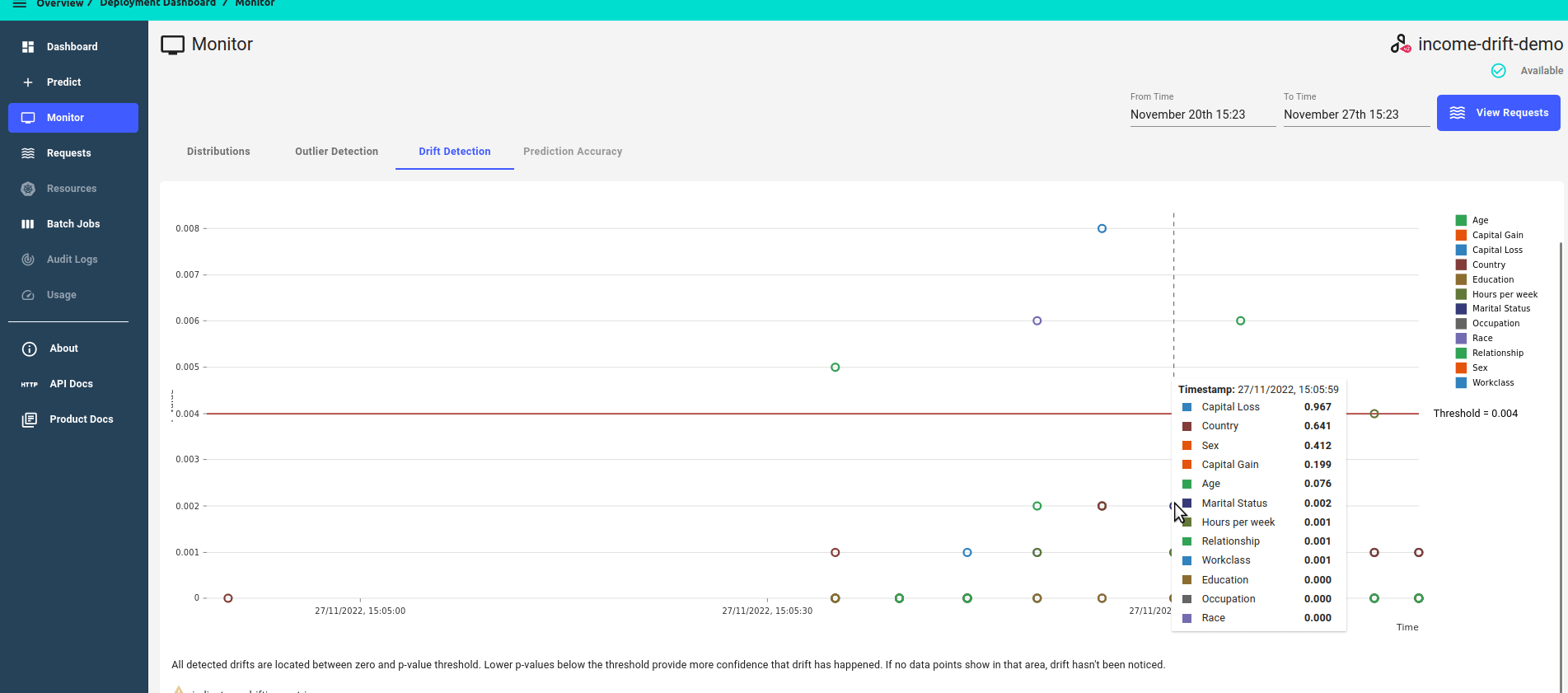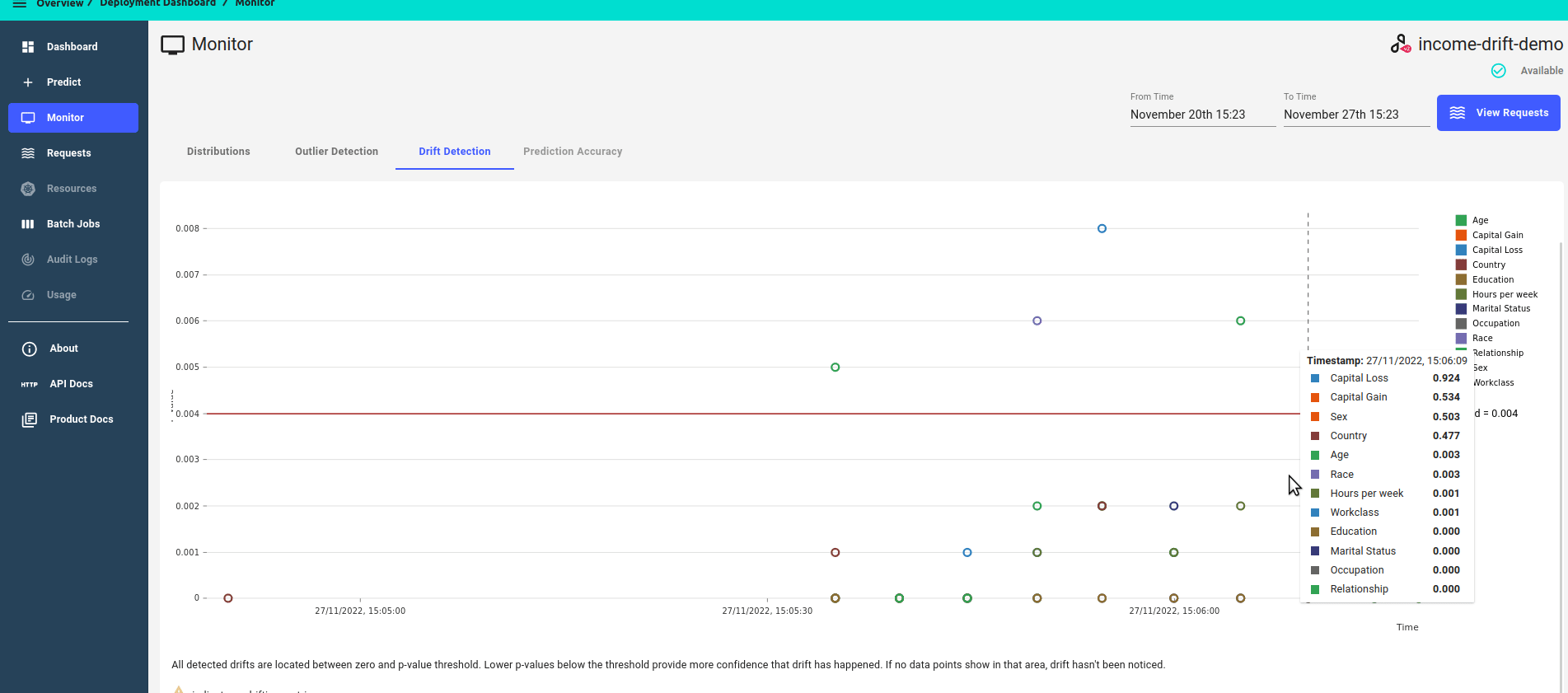
Zoomed out view, showing all features
Distance score over time.
Monitor Drift Detection Alerts¶
If you have alerting configured you should see a notification about the drift
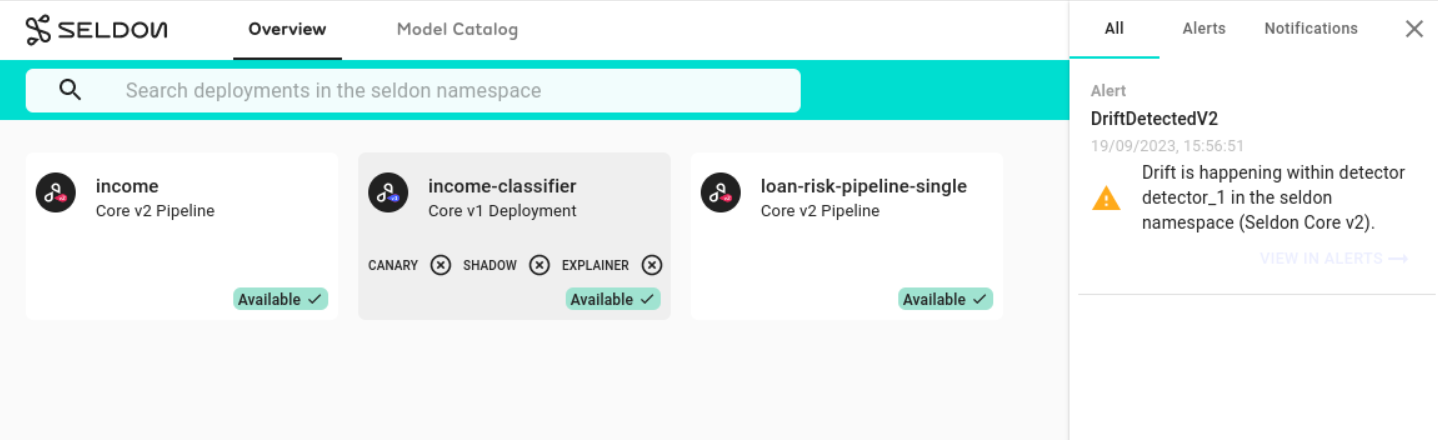
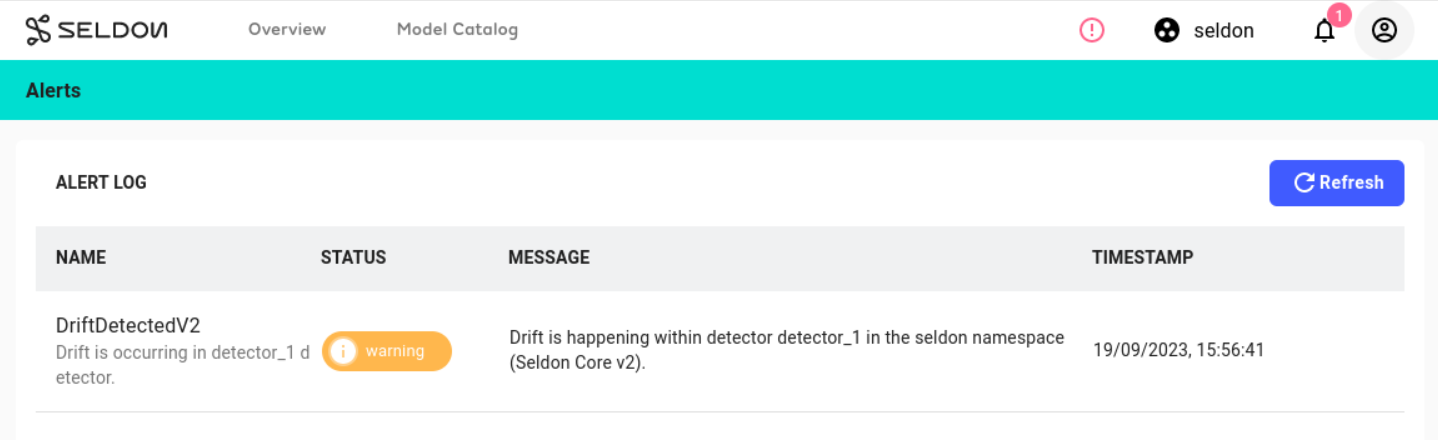
with further details present on the alerting log
Data drift and reference distributions comparison¶
To further analyse prediction data drift, you can also switch to the feature distribution tab to compare predictions to reference data distribution. See feature distribution monitoring demo for setup details.
Upload the income classifier reference dataset as the reference data to monitor data drift in terms of feature distributions. Once reference data is available, you can compare the distributions of the prediction data to the reference data.
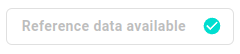
Expand to see reference data available
You can see when reference data is available by checking the button on the top left of the DISTRIBUTIONS dashboard. If it is not clickable and displays REFERENCE DATA AVAILABLE, then reference data is available.
For each feature, you can click on Toggle reference data to view reference data side by side.
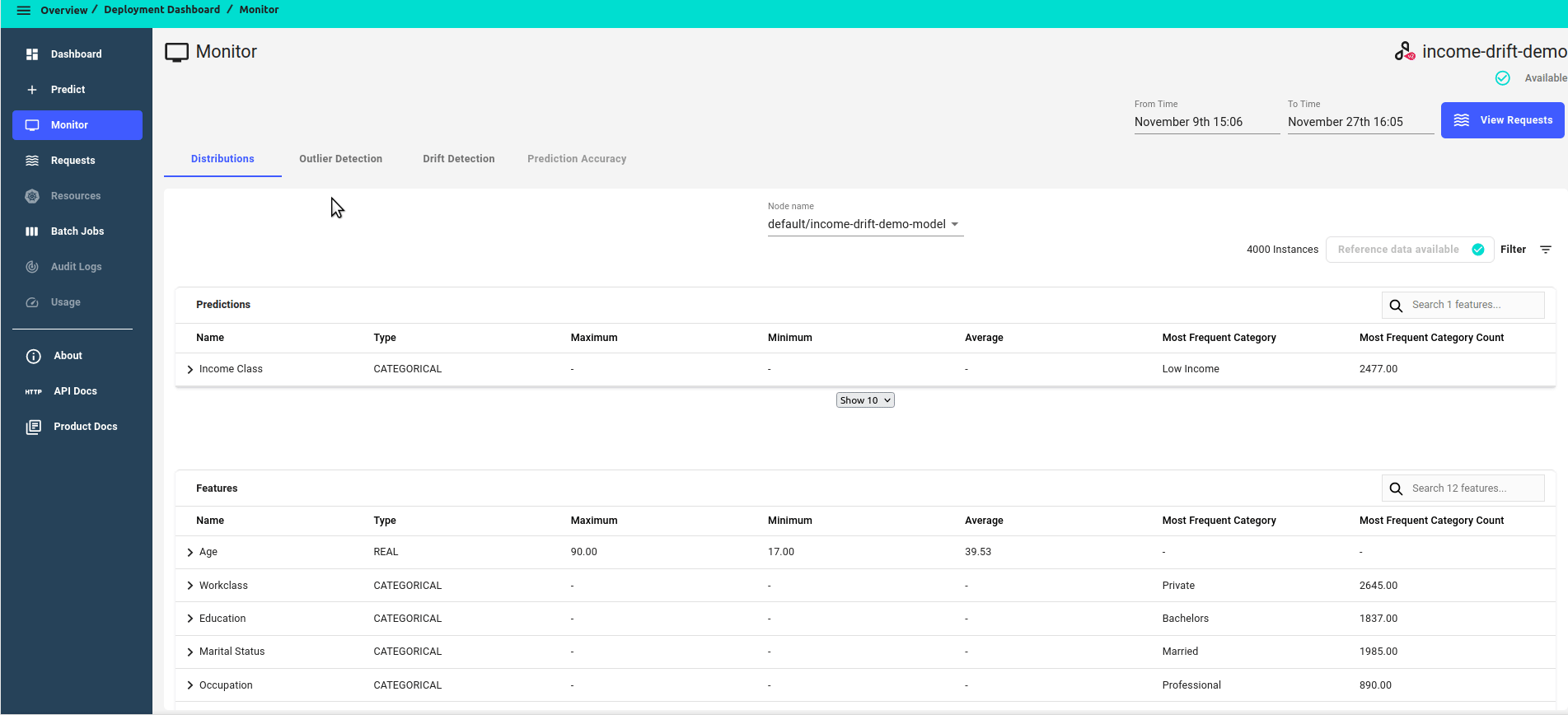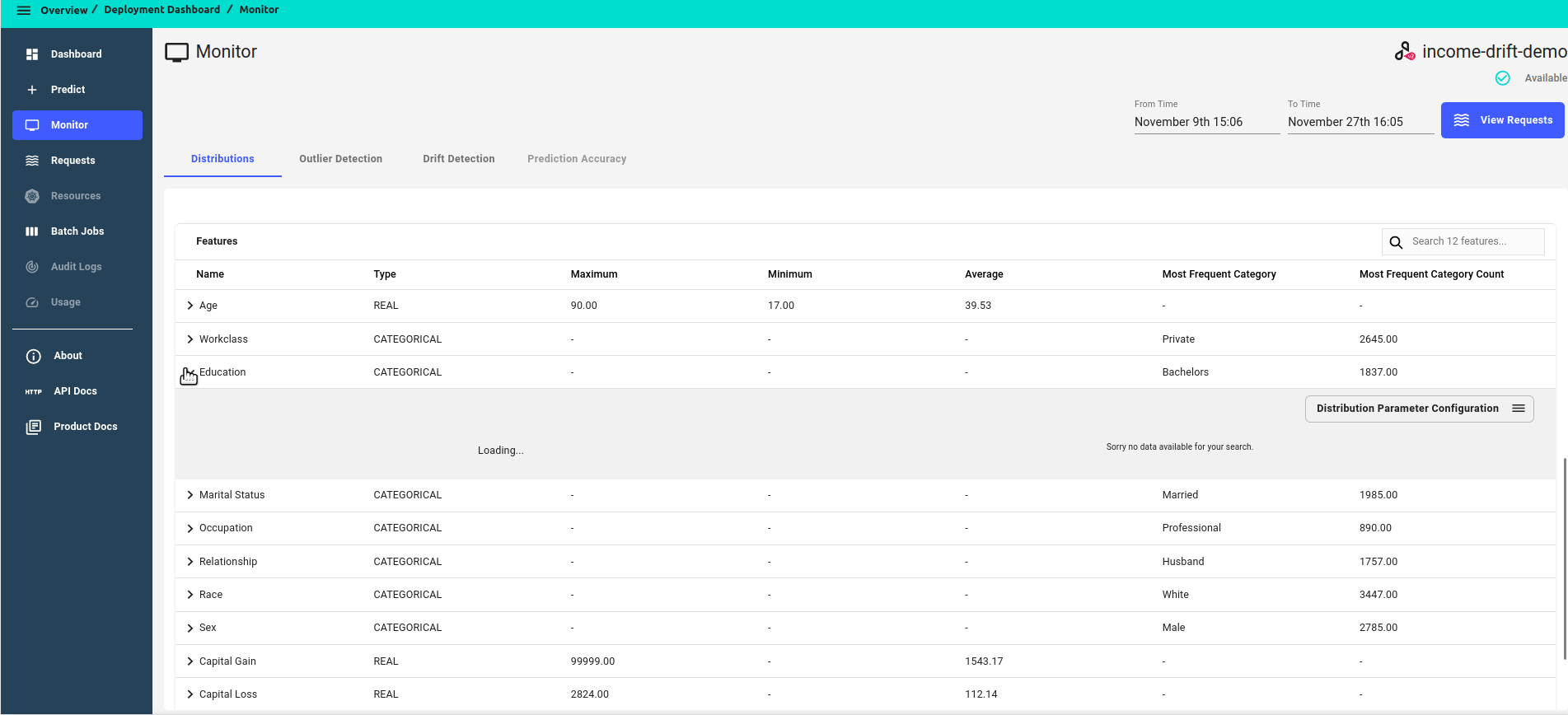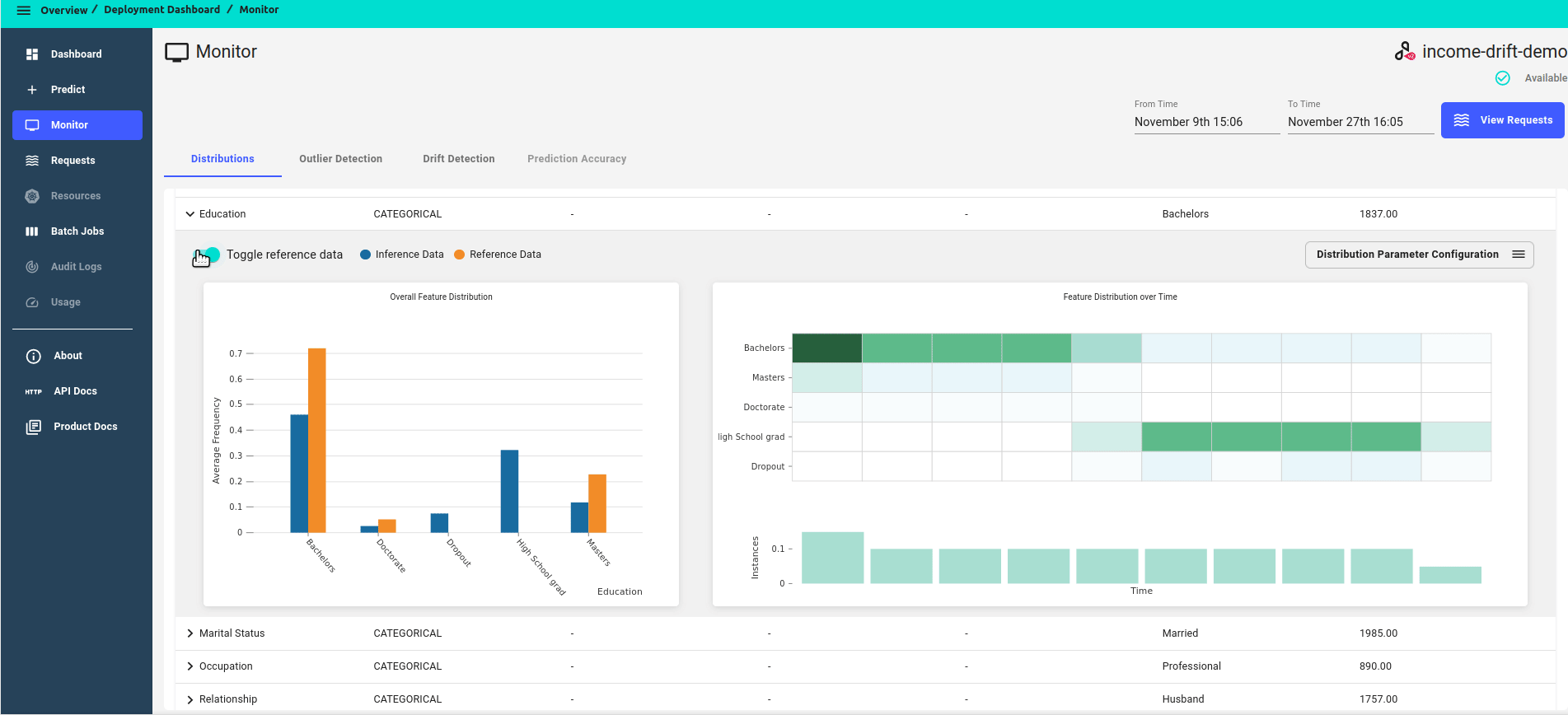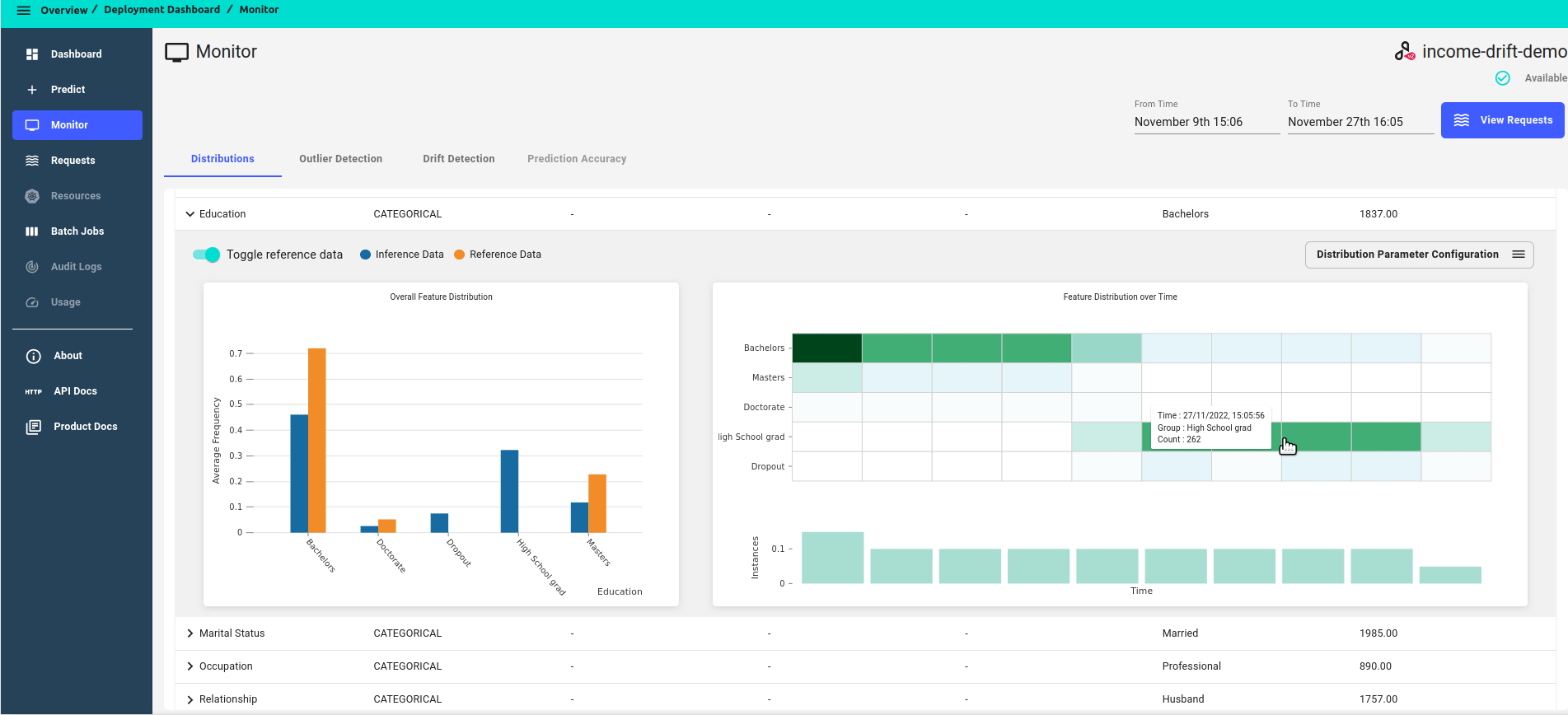
We will see that the drifted data has lower education individuals that were not in the reference data.
Troubleshooting¶
If you experience issues with this demo, see the troubleshooting docs or Elasticsearch sections.