 Seldon Enterprise Platform Documentation Update
Seldon Enterprise Platform Documentation Update
Text Generation with Custom HuggingFace Model¶
In this demo we will:
Launch a pretrained a custom text generation HuggingFace model in a Seldon Pipeline
Send a text input request to get a generated text prediction
The custom HuggingFace text generation model is based on the TinyStories-1M model in the HuggingFace hub.
Create Model¶
Click on
Create new deployment.Enter the deployment details as follows:
- Name: hf-custom-tiny-stories - Namespace: seldon - Type: Seldon ML Pipeline
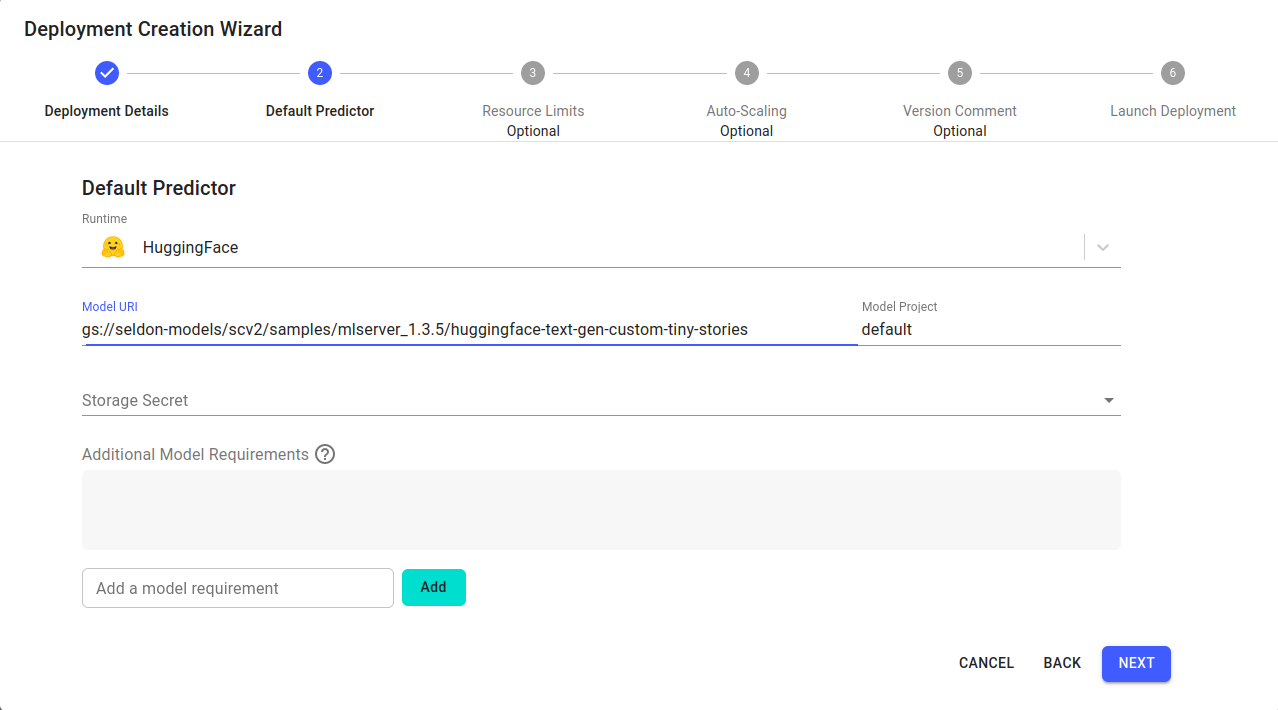
Configure the default predictor as follows:
- Runtime: HuggingFace - Model Project: default - Model URI: gs://seldon-models/scv2/samples/mlserver_1.3.5/huggingface-text-gen-custom-tiny-stories - Storage Secret: (leave blank/none)
Skip to the end and click
Launch.If your deployment is launched successfully, it will have
Availablestatus.
Get Predictions¶
Click on the
hf-custom-tiny-storiesdeployment created in the previous section to enter the deployment dashboard.Inside the deployment dashboard, click on the
Predictbutton.On the
Predictpage, enter the following text:{ "inputs": [{ "name": "args", "shape": [1], "datatype": "BYTES", "data": ["The brown fox jumped"] }] }
Click the
Predictbutton.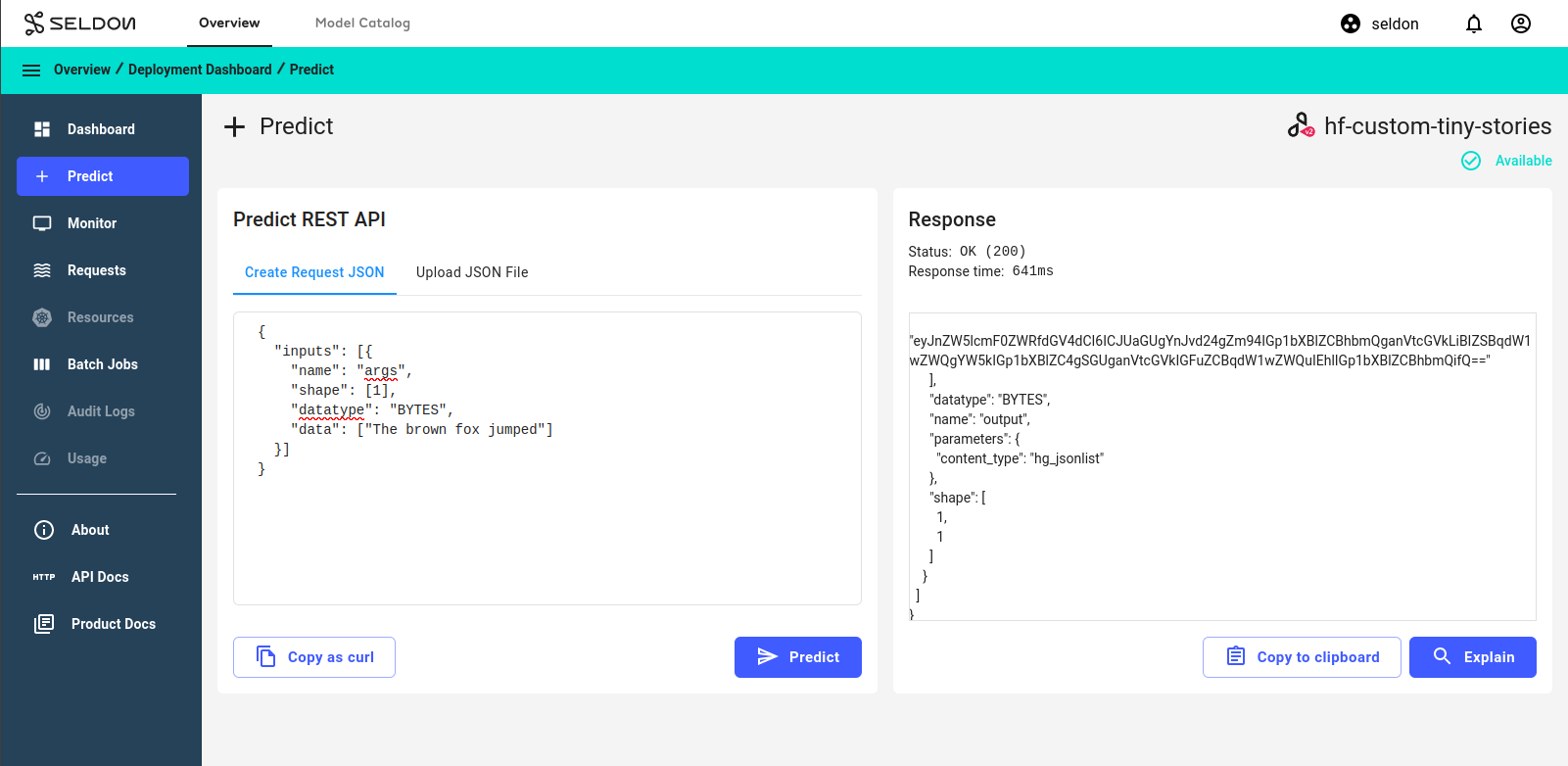
Congratulations, you’ve successfully sent a prediction request using a custom HuggingFace model! 🥳
Next steps¶
Why not try our other demos? Or perhaps try running a larger-scale model? You can find one in gs://seldon-models/scv2/samples/mlserver_1.3.5/huggingface-text-gen-custom-gpt2. However, you may need to request more memory!